[toc]
hello,大家好,我是聪聪。
最近在重构一款底层数据加解密中间件,里面有一些内容需要解耦:
- 针对不同数据源处理单独,MySQL、MongoDB、ES数据源进行加解密处理。
- 可插拔扩展不同加解密算法。
- 兼容不同日志框架做数据脱敏,自定义客制化脱敏规则。
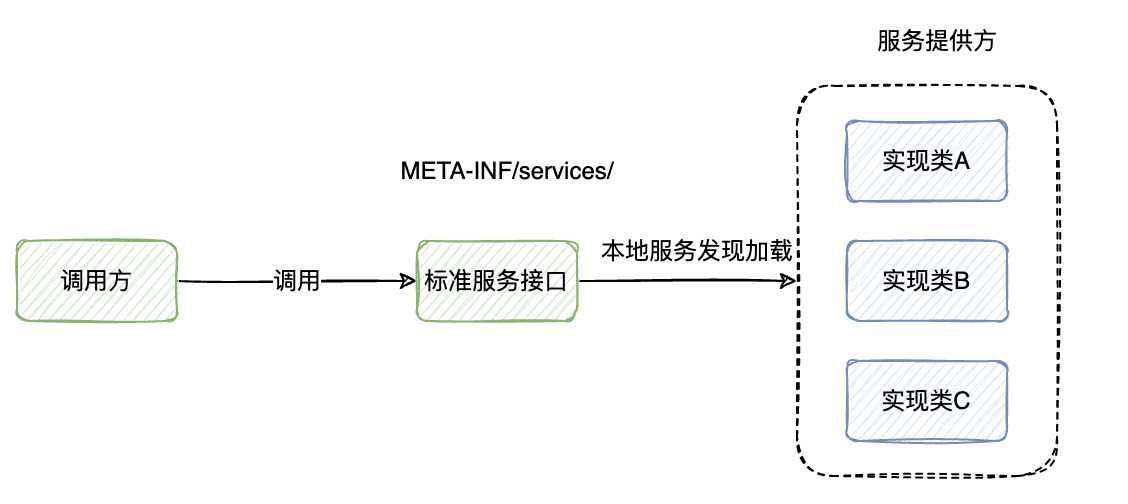
在这里设想通过SPI机制,让接入业务方可进行插件客制化扩展。 中间件内提供业务通用AES加解密方法,同时提供接口业务方自行扩展其他加解密算法:RSA等。 那么就在这里总结一下SPI机制是什么。
# 1.介绍
SPI 全称为 Service Provider Interface,是一种服务发现机制。通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。通常用来实现扩展第三方API,进行插件替换。
之前介绍过一篇Dubbo中的SPI机制,Dubbo中扩展点机制是对JDK的SPI进行了深度加强,解决了JDK SPI的一些痛点问题:
- JDK标准SPI机制会一次性将所有实现进行加载(Iterator方式),无论使用与否。如果实现类初始化过程较耗时,在加载上会很浪费资源。
- 如果扩展点加载失败,也就连扩展点实现类的名称也无法拿到。
- 增加了对扩展点的IoC和AOP的支持,一个扩展点可以直接setter注入其他扩展点。
详细内容可以参考Dubbo-ExtensionLoader (opens new window) 这篇文章。
# 2.使用介绍
按照上面SPI的思想我们下面实现一个小例子。
# 2.1 定义一个标准接口
package cc.ccoder.cipher;
public interface CipherStrategy {
/**
* 加密处理
*
* @param plainText 明文
* @return 加密结束后返回密文,异常时原文本
*/
String encrypt(String plainText);
/**
* 解密处理
*
* @param ciphertext 密文
* @return 解密结束后返回明文,异常时返回原文本
*/
String decrypt(String ciphertext);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 2.2 定义实现类
上面定义的接口可以理解为一个规范,各服务提供方可自行实现。 下面就对上面接口进行实现。 实现内容便是该接口的具体业务逻辑实现,在这里简化处理,直接打印一句话。
- 实现一:AES加解密处理
package cc.ccoder.cipher;
public class AESCipherStrategy implements CipherStrategy {
@Override
public String encrypt(String plainText) {
System.out.println("AES加密处理");
return plainText;
}
@Override
public String decrypt(String ciphertext) {
System.out.println("AES解密处理");
return ciphertext;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 实现二:RSA加解密处理
package cc.ccoder.cipher;
public class RSACipherStrategy implements CipherStrategy {
@Override
public String encrypt(String plainText) {
System.out.println("RSA加密处理");
return plainText;
}
@Override
public String decrypt(String ciphertext) {
System.out.println("RSA解密处理");
return ciphertext;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 2.3 定义配置文件
需要在classpath路径下定义一个配置文件。
- 文件名称为:接口全限定类名
- 文件内容为:实现类的全限定类名,多个实现类用换行符分割

cc.ccoder.cipher.RSACipherStrategy
cc.ccoder.cipher.AESCipherStrategy
2
# 2.4 使用方式
上面已经使用SPI机制进行扩展实现CipherStrategy接口,并且存在两个扩展点RSACipherStrategy、AESCipherStrategy。
通常情况下标准接口定义为规范,扩展点实现为不同服务提供方实现,从而实现可插拔解耦。
例如:Java提供数据库驱动接口java.sql.Driver,不同数据库提供商对其进行实现。并且我们也能够在该数据库提供商的client 依赖中找到SPI定义的实现类名称。MySQL可以在mysql-connenctor-java依赖中的META-INF/services中找到对java.sql.Driver接口的实现:com.mysql.jdbc.Driver。
看下面代码:
public static void main(String[] args) {
//java.util中ServiceLoader
ServiceLoader<CipherStrategy> load = ServiceLoader.load(CipherStrategy.class);
//sun.misc中Service
Iterator<CipherStrategy> providers = Service.providers(CipherStrategy.class);
for (CipherStrategy cipherStrategy : load) {
cipherStrategy.encrypt("test");
}
System.out.println("----------");
while (providers.hasNext()){
CipherStrategy cipherStrategy = providers.next();
cipherStrategy.encrypt("test");
}
}
// 以下为输出结果
RSA 加密处理
AES 加密处理
----------
RSA 加密处理
AES 加密处理
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
我们可以通过ServiceLoader.load()或Service.providers()方法获取到该标准接口的扩展点类实现。如上注释所示两种方式提供方不一样。
ServiceLoader.load()为java.util.ServiceLoader提供。Service.providers()为sun.misc.Service提供。
如上输出结果所示:两种方式执行顺序、执行结果一致。
肯定有人会说:这就是策略模式、接口多实现而已,为何还要如此复杂定义配置文件呢? 这里要明确一个场景: 接口定义、接口实现并不在一个服务、一个包中。 假设:开发中间件时,通常定义一个加解密接口、路由转发接口、熔断策略方案等,在中间件中可以提供一种常用、通用的默认实现方式,若业务方或引入方存在特殊场景需要自行实现以上接口时,是不是就不好处理了,必须推送中间件进行提供该能力了。 因此,可以使用SPI机制进行暴露接口,业务方自行实现,从而实现扩展功能,可插拔插件式开发。 顺便说一下Java中默认提供了SPI机制,但是该机制存在一些痛点,介绍部分已经说明。Dubbo中对该SPI机制进行重写为ExtensionLoader方法,能够实现更加强大的插件式开发。
Dubbo 强大的服务治理能力不仅体现在核心框架上,还包括其优秀的扩展能力以及周边配套设施的支持。通过 Filter、Router、Protocol 等几乎存在于每一个关键流程上的扩展点定义,我们可以丰富 Dubbo 的功能或实现与其他微服务配套系统的对接,包括 Transaction、Tracing 目前都有通过 SPI 扩展的实现方案,具体可以参见 Dubbo 扩展性的详情,也可以在 apache/dubbo-spi-extensions (opens new window) 项目中发现与更多的扩展实现。
# 3.源码分析
言归正传,接下来看看ServiceLoader.load()源码中是如何加载获取到接口的实现类。
我们根据ServiceLoader.load()方法进入源码中捋一捋SPI是如何加载获得到实例的。
# 3.1 类成员变量梳理
如下源码所示:先梳理ServiceLoader中常用的重要成员变量。
注意:部分源码已删除,可忽略。
public final class ServiceLoader<S> implements Iterable<S>{
// 指定加载目录,配置文件目录,classpath目录下,用来查找该目录中的接口扩展点实现。
private static final String PREFIX = "META-INF/services/";
// 表示当前正在被加载的类或者接口,例如此处便是我们定义的标准接口:CipherStrategy
private final Class<S> service;
// 类加载器,用来定位、加载、实例化接口实现(实例化下面providers的类加载器)
private final ClassLoader loader;
// 访问控制上下文,后续通过反射创建接口实现类时候需要使用
private final AccessControlContext acc;
// 已被加载的服务类集合,按照顺序,注意此处是LinedHashMap 链表存在顺序的。
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 内部类,当前懒加载服务类,也是真正的类加载器。
private LazyIterator lookupIterator;
//省略其余逻辑代码...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这样,我们就有了大致脉络:
- 定义类加载器
ClassLoader,用来加载、实例化接口实现类。至于说该类加载器来源是哪里,后续源码有说明。 - 扩展点加载目录,JDK已固定。
- 已被加载的扩展类集合,使用
LinkedHashMap存储,按照配置文件顺序。 - 扩展类加载机制,在内部类
LazyIterator中实现。 - 实现
Iterable接口,为后续迭代所有扩展点实现类时做铺垫。
ServiceLoader.load()方法中存在两个重载方法:
ServiceLoader<S> load(Class<S> service)- service 为当前扩展点接口类
- 使用的类加载器为当前线程的类加载器。
Thread.currentThread().getContextClassLoader()。 - 调用下面加载方法。
ServiceLoader<S> load(Class<S> service, ClassLoader loader)- service为当前扩展点接口类
- 使用指定类加载器。
- 内部实例化构造器,在构造器中对上述成员变量进行定义说明。
- 重新加载
reload()所有服务类加载集合。 - 调用
LazyIterator构造方法,初始化该懒加载。此时并没有真正实例化加载类。 - 调用
hasNext()迭代时进行加载扩展点实现类。
# 3.2 查找实现类
查找实现类及创建实现类的过程均在内部类LazyIterator中完成。当我们调用providers.hasNext()或providers.next()时,均是内部类LazyIterator的方法,实现Iterator的方法。
因此我们着重关注一下LazyIterator.next()方法,其中最终会调用到hashNextService()方法,详细细节看下面源码:
private class LazyIterator implements Iterator<S>{
// 一些成员变量,下面根据源码说明成员变量含义。
// 接口类,此处便是定义的标准接口CipherStrategy
Class<S> service;
// 类加载器
ClassLoader loader;
// 接口全限定类名转化成URL
Enumeration<URL> configs = null;
// 迭代器
Iterator<String> pending = null;
String nextName = null;
//内部构造行数,在ServiceLoader的构造函数中进行初始化加载
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
// 迭代时,判断是否存在实现类名称
// 第一次加载时为空 继续执行
// 第二次加载时已经解析完成,直接返回。
if (nextName != null) {
return true;
}
if (configs == null) {
try {
// PREFIX : 定义的加载目录 : META-INF/services/
// fullName 加载目录+ 接口类的全限定类名,就可以定位到该接口的配置路径.
// META-INF/services/cc.ccoder.cipher.CipherStrategy
String fullName = PREFIX + service.getName();
if (loader == null)
//类加载器为空时 ServiceLoader构造器中未指定,才用系统默认类加载器进行加载接口全限定类名
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
//迭代器初始化为空 或者 没有下一个元素时进入循环
while ((pending == null) || !pending.hasNext()) {
// 接口文件中没有多余元素时
if (!configs.hasMoreElements()) {
return false;
}
//解析
pending = parse(service, configs.nextElement());
}
//解析完成
nextName = pending.next();
return true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
上面逻辑更多的是判断当前接口在配置文件中是否存在实现类定义,如果存在则继续next()方法获取,在next()逻辑中则是使用nextService()方法真正的拿到接口类的实现类。
# 3.3 实例化接口实现类
下面逻辑就是通过nextName 接口实现类全限定类名拿到该接口实现类的class对象,并且将其实例化的过程。当然也将实例化对象放入定义好的LinkedHashMap集合中。 到此,源码部分便结束了。 拿到了接口实现类的对象实例了,那么接下里的便是业务运用过程,可以为所欲为的使用啦。
private S nextService() {
//接口文件中不存在实现类记录时 直接抛出NoSuchElementException异常
if (!hasNextService()) throw new NoSuchElementException();
//接口全限定类名
String cn = nextName;
nextName = null;
//接口实现类class对象
Class<?> c = null;
try {
//接口实现类的class对象
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service, "Provider " + cn + " not found");
}
// 判断实现类和几口的参数类型是否一致 ,否则直接fail返回
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
try {
//通过newInstance实例化对象
S p = service.cast(c.newInstance());
//将对象放入放入实现类集合中 并且返回对象.
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service, "Provider " + cn + " could not be instantiated", x);
}
throw new Error(); // This cannot happen
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 4.应用场景
SPI机制在日常开发中经常会遇到,只是我们关注使用中间件功能,忽略了其本质如何实现扩展、灵活插件可插拔的。
# 4.1 JDBC使用场景
从上面接口实现类的class对象实例化逻辑可以看到很熟悉的方法:Class.forName()方法。
在我们最开始使用JDBC连接MySQL数据库时,就是先何止数据库连接驱动,再通过DriverManager获得一个数据库连接。
String url = "jdbc:mysql://localhost:3306/test_db";
String user = "root";
String password = "chencong";
Class<?> aClass = Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection(url, user, password);
2
3
4
5
# 4.1.1 加载驱动
我们继续查看DriverManager类是如何加载数据库驱动的。
private static void loadInitialDrivers() {
//省略其余逻辑...
String drivers;
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
//ServerLoader加载SQL 驱动接口 java.sql.Driver
//加载接口java.sql.Driver的实现类:
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
//逐个加载校验
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
for (String aDriver : driversList) {
try {
//逐个实例化加载
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 4.1.2 创建Driver实例
上面已经通过java.sql.Driver全限定类名加载到了MySQL的实现类,那么就应该通过next() 方法去初始化实现该类。实现类只完成了:向DriverManager中注册MySQL的Driver实现类。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
//向DriverManager注册MySQL Driver驱动实现类
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
public Driver() throws SQLException {
// Required for Class.forName().newInstance()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 4.1.3 获取Connection连接
在DriverManager.getConnection()方法中获取数据库连接信息。
这里便是循环加载所有已经注册到DriverManager中的Driver实现类,调用连接connect方法获得数据库连接connection,并且返回。
private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException {
//类加载器获取,有则使用,无则获取当前线程类加载器。
ClassLoader callerCL = caller != null ? caller.getClassLoader() : null;
synchronized(DriverManager.class) {
// synchronize loading of the correct classloader.
if (callerCL == null) {
callerCL = Thread.currentThread().getContextClassLoader();
}
}
//省略部分判断校验逻辑...
//循环加载registeredDrivers列表中的渠道,该列表来源于实现类向其中注册。
for(DriverInfo aDriver : registeredDrivers) {
// 判断逻辑:判断当前渠道实现类是否可以正确加载得到。
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
//获取数据库连接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// Success!
println("getConnection returning " + aDriver.driver.getClass().getName());
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println(" skipping: " + aDriver.getClass().getName());
}
}
//获取数据库连接失败,打印一些异常信息,已省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 4.1.4 自定义扩展实现类
上面我们知道了JDBC数据库连接创建过程,我们按照SPI的机制自定义一个数据库连接方式,并且可以修改、添加一些信息。理论上可以完成。
- 创建一个自定义Driver类,取名为
CustomDriver继承NonRegisteringDriver实现java.sql.Driver接口。 - 在
META-INF/services目录下创建一个java.sql.Driver文件,文件内容为我们自定义CustomDriver类的全限定类名。
public class CustomDriver extends NonRegisteringDriver implements Driver {
static {
try {
java.sql.DriverManager.registerDriver(new CustomDriver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
/**
* Construct a new driver and register it with DriverManager
*
* @throws SQLException
* if a database error occurs.
*/
public CustomDriver() throws SQLException {}
@Override
public Connection connect(String url, Properties info) throws SQLException {
// 这里父类NonRegisteringDriver 中完成数据库连接信息
System.out.println("CustomDriver数据库连接url:" + url);
System.out.println("CustomDriver数据库连接信息:" + info);
Connection connect = super.connect(url, info);
System.out.println("CustomDriver数据库连接加载完成:" + connect);
return connect;
}
}
//输出信息如下:
Connected to the target VM, address: '127.0.0.1:51817', transport: 'socket'
CustomDriver数据库连接url:jdbc:mysql://localhost:3306/test_db
CustomDriver数据库连接信息:{user=root, password=chencong}
CustomDriver数据库连接加载完成:com.mysql.cj.jdbc.ConnectionImpl@48e1f6c7
Disconnected from the target VM, address: '127.0.0.1:51817', transport: 'socket'
Process finished with exit code 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
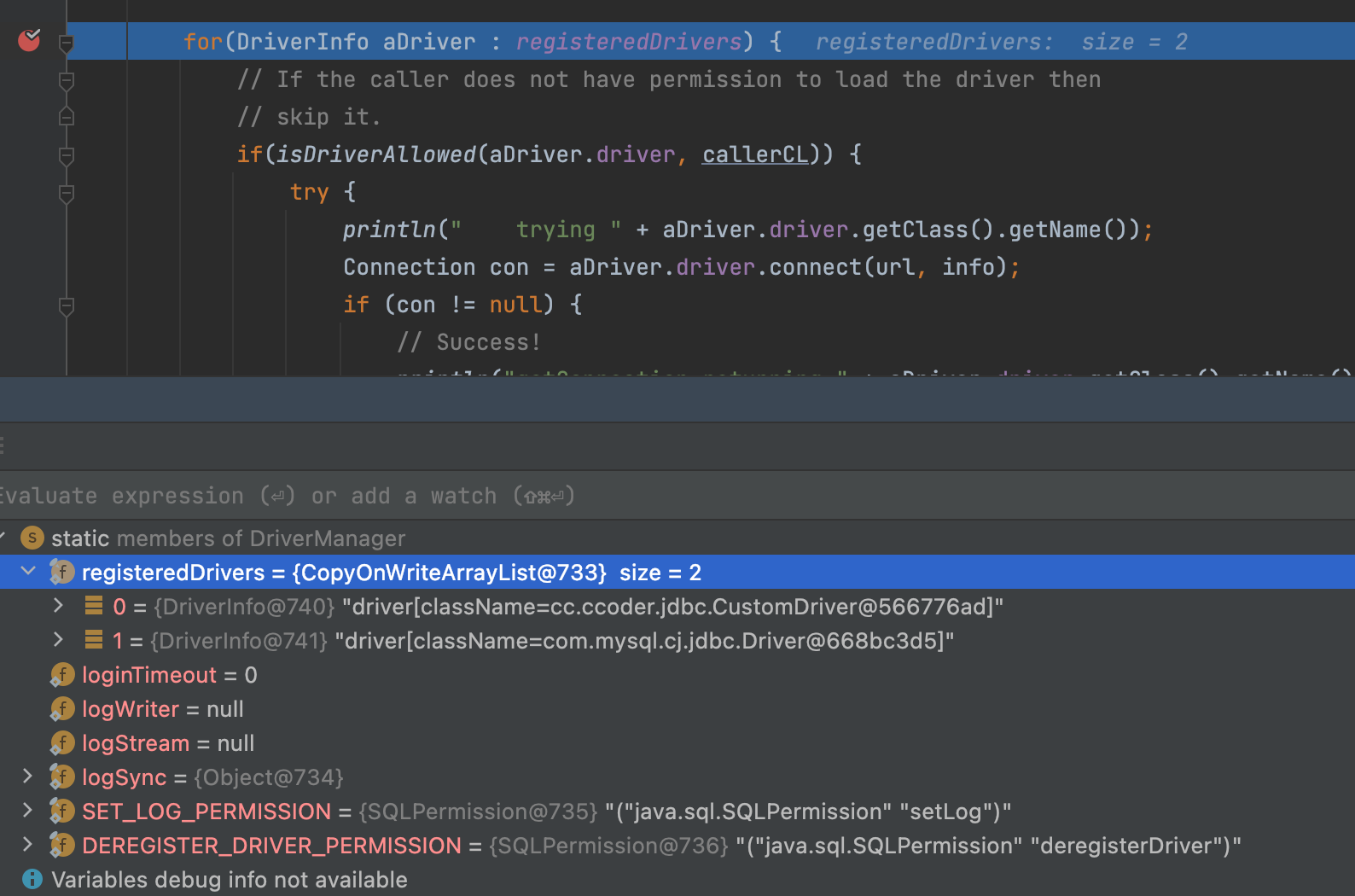
从上面输出打印信息可以看到,加载数据库驱动实现类时已经加载到我们自定义CustomDriver类中,因为我们继承了NonRegisteringDriver类,所以数据库连接信息最终还是由该类完成。
同时我们也可以在DriverManager中看到目前java.sql.Driver存在两个实现类。
# 4.2 ValidationProvider 数据校验
数据校验是可以避免写大量if-else逻辑进行校验判断,并且可以通过文档化入参格式限制。
ValidationProvider接口提供了系列抽象功能。
hibernate-validator依赖中对其功能做具体扩展实现,同样也是通过SPI机制实现。
后面可以专门总结一下常用的数据校验方式,以及实际基础类打点校验是如何实现和实践的。
# 5.Dubbo、Spring、JDK三种SPI机制区别
| JDK SPI | Dubbo SPI | Spring SPI | |
|---|---|---|---|
| 文件加载方式 | 每个扩展点接口一个文件 | 每个扩展点接口一个文件 | 所有扩展点一个文件spring.factories |
| 是否支持获取固定实现 | 不支持,只能按照顺序加载所有实现, | 具有"别名",可以通过名称获取扩展点具体实现,一般配合Dubbo SPI主机使用 | 不支持,按照顺序加载。但是有Spring Boot ClassLoader会优先加载用户自定义的spring.factories文件,可以保证用户自定义factory方式在第一个。 |
| 其他 | 无 | 支持Dubbo内部的依赖注入,通过目录来区分Dubbo 内置SPI和外部SPI,优先加载内部,保证内部的优先级最高 | 无 |
全文结束。
了解更多内容,可以关注我的微信公众号,更多首发文章。
